
Zoo. For Little Me, that word never inspired that much excitement. I never really did appreciate going to the zoo as much as I should have. 1
The only animals I really found noteworthy were the gorillas, who seemed equally starved for entertainment. 2 I unintentionally mimicked the gorilla habit of knuckle-walking on all fours when my feet got tired from traveling to exhibit after exhibit.
I only understood what the zoo signified when I reached adulthood. People go there for variety. You can see big guys with really long necks, sun-fed and beady-eyed Michael Kors handbag material, permanently aggro but splendidly colorful squawkers, and…clears throat…official property of the People’s Republic of China generously loaned to demonstrate good will towards the American people. 3
Computer modeling and simulation is also a zoo, full of strange and exotic creatures that consume CPU cycles (and lately, Nvidia graphics cards) instead of bamboo shoots. This ongoing series will cover various simulation systems used for research, fun, and other myriad things. The focus will be on some of the most interesting tangible and intangible features of these systems and their context of usage.
I am going to start off with several posts focusing in particular on agent-based modeling and simulation (ABMS) platforms. Since ABMS ideas and their mechanical implementation are somewhat esoteric this post is mainly going to talk about conceptual issues on the periphery of ABMS platform structures and practices.
Boffins gone wild
The COVIDSim Saga
It’s not every day that something relatively niche you’re interested in makes headlines. However, four years ago agent-based modeling and simulation actually did! The monkey’s paw sure did curl, though.

The year was 2020.
Just like all the rest of you, I was helplessly watching everything shut down. I had lost any sense of time and didn’t really understand what was going on in the outside world. Those were truly strange times. I was so screwed in the head that I was even letting YouTube “video essayists” meme me into thinking that Aliens: Colonial Marines was a “misunderstood classic.”
Yes, I snapped out of it, but things were truly looking dire.
Then, just when I thought all was lost, I saw something ABMS-related appear on the news. They were finally seeing the light. I now had an excuse to ramble about yet another convoluted topic to my friends, relatives, and pretty much anyone else within (figurative) earshot. Some “boffins” at Imperial College London — led by Neil Ferguson — made an ABMS and people were talking about it! 4
Yes, the COVIDSim ICL came up with was an ABMS (sort of):
The Ferguson model is an example of an agent-based epidemiological model: it models the spread of disease down at the level of individuals and their contacts. At the heart of such a model is a graph representing a network of social contacts, with vertices corresponding to individuals, and edges indicating a social contact, and hence a possible route for infection. This is then overlaid with a model of how the disease spreads through the network, which at its crudest might be a probability that a disease will spread from one infected individual to another individual with whom they have contact. Given such a model and an initial state of the network, it is computationally a relatively straightforward matter to simulate how infection spreads, although of course since the models are stochastic, different simulations will yield different results. The Ferguson model is much richer than this: makes a raft of assumptions about questions such how the disease spreads, whether asymptomatic individuals can infect others, how infection progresses through an individual to recovery or death, the infection fatality rate, the case fatality rate, and so on.
Note
I put the “sort of” qualifier here because it has been alternatively described as a “microsimulation” or a heavily tuned up variant of a standard epidemic model. These are not mutually exclusive with ABMS — after all many classic ABMS programs are hybridized. I do think that it is more ABMS — or, as biologists say, “individual-based” — than not. If you want to learn more about these categories take a gander at this book.
As it turned out, the ICL simulation strongly influenced UK COVID policy. Incorporating unpredictable mass behavior into pandemic decision-making is incredibly challenging. So it wasn’t surprising that British authorities found use for ABMS. How, exactly, COVIDSim and other expert inputs influenced lockdown policy choices is also predictably thorny.
That escalated quickly
The more important thing was that British people were mad!
Neil Ferguson isn’t single-handedly responsible for this world-historical blunder, but he does bear some responsibility. His apocalyptic predictions frightened the British Government into imposing a full lockdown, with other governments quickly following suit. And I’m afraid he’s absolutely typical of the breed. He suffers from the same fundamental arrogance that progressive interventionists have exhibited since at least the middle of the 18th Century – wildly over-estimating the good that governments can do, assuming there are no limits to what “science” can achieve and, at the same time, ignoring the empirical evidence that their ambitious public programmes are a complete disaster. At bottom, they believe that nature itself can be bent to man’s will.
British people getting mad at things is, in and of itself, not especially noteworthy. Every time I try to read British newspapers, I come across opinion articles written by stone-faced men or women ranting about some mundane feature of everyday life. “Youth routinely cross the street without looking me in the eye,” “Parliament must explain why Peppa Pig is so abnormally tall,” and “how dare dogs and their arrogant owners ruin my Michelin-starred dinner.” 5
I am no stranger to the odd bizarre psychological hangup, but I must say there is something really lost in translation here. So while regrettable, I was inclined to ignore the affair. Then somehow fellow Americans got looped into it:
Elon Musk calls Ferguson an “utter tool” who does “absurdly fake science.” Jay Schnitzer, an expert in vascular biology and a former scientific direct of the Sidney Kimmel Cancer Center in San Diego, tells me: “I’m normally reluctant to say this about a scientist, but he dances on the edge of being a publicity-seeking charlatan.”
Clearly, there was something much bigger going on here. I wanted to learn more, but unfortunately things here in the States got crazier and controversy over a British simulation model faded into the background. After things opened up here and calmed down a bit, I decided to look more into what happened with COVIDSim and figure out what had happened.
Admittedly, much of it pertained to British domestic political matters I don’t understand well enough to say anything about. But I gathered there were several interrelated complaints about COVIDSim:
- The conceptual assumptions were wrong
- The computational implementation was bad
What was the end verdict? I don’t have enough time and space here to really talk about it in granular detail, but COVIDSim was eventually reproduced and validated by external observers. Ferguson himself did not exactly emerge from the entire affair looking as inept as his critics alleged either.
What seems particularly clear in hindsight, at least, is that the technical features of ICL’s ABMS program were integral to the fracas. While there were many different issues interacting in the controversy (not all of which were ICL’s fault), “software janitor” problems run through a good deal of them.
Note
I am not really sure there is a better term for this. Questions like “does the user know what a filesystem is? Can they use the command line?” do not really even begin to cover it. Paul Dourish wrote a very good article about all of the ancillary things that programs do beyond purely serving as containers for algorithms. Reading files from disks, connecting to servers, responding to user input, outputting to log files, checking for free space are all in some sense the responsibility of a program even if they may not be a core function. And in the context of software use the kludge underneath the graphical user interface is assumed knowledge for doing anything beyond word processing, web surfing, and other basic user functions. Yet unless you find any of this intrinsically exciting it may seem as tedious as sweeping up the floors after hours.
A suitable modeling environment
COVIDSim’s software architecture and organization — and, more specifically, the fact that it was a giant, poorly documented, 15,000-line C file — gave ammunition to critics of the policies it influenced. John Carmack described it as possibly “machine translated from Fortran.” The mess reflected COVIDSim’s developmental history. The program was actually the descendant of several decades’ worth of other models and inherited their code.
COVIDSim was a boutique system. It wasn’t developed on a standard ABMS software platform. That’s understandable. The simulation had a long gestation period and ABMS itself (born in the mid-90s) has an uneven software history. It is reasonable to suggest that a more professional and streamlined approach to software development might have made COVIDSim more robust to what likely would have been inevitable criticism.
Agent technology pioneer Michael Woolridge, in his 2020 review of the COVIDSim controversy, called for (among other things) better ABM tooling. C was not an appropriate choice for writing and testing something as niche and exotic as an ABMS program. The software structure was overly monolithic and made the codebase unwieldy and difficult to keep track of. Simulation assumptions were buried in the messy code.
There were also more abstract issues raised with the predictive ability of the simulation and whether its randomness and non-determinism made its results hard to reproduce. But I will skip to the end and relay Woolridge’s most important constructive recommendation.
Better modeling environments. We need software environments that are better able to directly capture agent-based models of the kind used in the Ferguson model. A suitable programming environment will make assumptions explicit, and allow developers to focus on the model itself, rather than how the model is expressed in a low-level programming language. A suitable software environment will need to scale to national and ideally global models with millions, and possibly billions of agents.
That was four years ago. How have things gone since? Let’s highlight two basic desired features of a superior modeling environment:
- Assumptions should be made explicit.
- Developers should be able to focus on the problem, not how it is programmed.
These are sound objectives. However, in the case of ABMS — and quite frankly many other simulation and modeling frameworks applied to problems outside of the physical sciences --- there may be an unbridgeable chasm in between them. It will take time to explore the nature of that chasm — in theory, the machines people use to model the theories, and the practices associated with them.
I am going to spend the rest of this post on the ideas behind ABMS and simulation modeling in general.
Thursday nights at El Farol
This is not an ABMS primer
This is now an appropriate time to describe what ABMS actually is, for those who are not already familiar with it. I do not intend to give the reader a tutorial in ABMS theory, practice, and implementation. There are entire books written about this! The most I can do in the time and space I have, for lay audiences, is to give a flavor of what the experience of working with ABMS programs is like.
You will hear people justify ABMS with woo-like language about how emergent results in complex social, natural, and engineered systems (or any combination of the three) arise from the bottom-up collective results of individual behaviors. That isn’t inaccurate. It can be taken to extremes and oversolid, but it is not wrong.
Yes, an ABMS is a stylized representation of a complex system in which interacting individual attributes and behaviors collectively lead to emergent outcomes. There are many individuals --- with simple decision-making procedures — that have some bounded ability to select actions, adapt to the environment, and learn how to modify their choices over time. And they are all simulated using computer software.
However, I’ve come to feel that this way of describing ABMS leaves out something very important. A big theme in this “zoo” series is that we underrate the influence of the “computer” side when it comes to computer modeling and simulation. What is actually most distinctive about ABMS is the “simulation” rather than “agent” part.
Go out or stay home

Since the pedagogical example might strike some readers as uncomfortably familiar, 6 I often like using the El Farol Bar Problem to introduce the idea of ABMS. And yes, it is a real place.
El Farol is a bar in Santa Fe, New Mexico. The bar is popular --- especially on Thursday nights when they offer Irish music --- but sometimes becomes overcrowded and unpleasant. In fact, if the patrons of the bar think it will be overcrowded they stay home; otherwise they go enjoy themselves at El Farol. [The problem] explores what happens to the overall attendance at the bar on these popular Thursday evenings, as the patrons use different strategies for determining how crowded they think the bar will be.
The El Farol Bar Problem can be represented as a game theory scenario, but it is popularly used as a simulation showcase. There is a very meaningful difference. We got computer chess programs because trying to implement game theory strategy selection methods for chess-playing didn’t work. The requirement of computational implementation created new formalisms that inherited ideas from game theory but qualitatively diverged from their ancestors.
But yes, back to El Farol. The people are trying to go to the bar. But they don’t want to go to an overcrowded bar. Every Thursday night, they have to make a decision: go or stay home. While each person in the problem isn’t consciously trying to anticipate the choices of other people making similar decisions, they do want to predict the aggregate result (the bar attendance) to make the best choice.
More specifically…for every “agent” (modeled person) in the problem, the following applies:
- They’ll only go to the bar on Thursday night if they think the number of people there won’t exceed their overcrowding threshold.
- Every week, they have access to the accumulated bar attendance figures from previous Thursdays.
- Each agent is randomly assigned a collection of strategies for predicting this week’s bar attendance.
- A strategy is how the agent should use past bar attendance to predict attendance for the current week.
- Agents decide what strategy to use by selecting the strategy that best performs over the past historical attendance data.
- The experimental variables you can tweak are:
- Overcrowding threshold
- How many past Thursdays can be remembered
- The amount of strategies agents can evaluate
This is, I’m afraid, a very crude oversimplification of the scenario. There is simply a limit to how much you can use words — especially words meant to make the scenario as simple as possible — to accurately describe a complex situation. Mathematical formulae are better but not sufficient either. This is a large part of why simulation is applied to the situation — it extends our descriptive and sensory capacities.
The real world quickly exhausts these capacities, especially when people make choices whose payoffs depend on the choices of a large number of other people. Through simulation, we can better imagine the whole without necessarily sacrificing our ability to think about individual aspects of it with some clarity and precision. Or at least that’s the advertised promise of it, anyway.
This is what the El Farol Bar Problem looks like in a popular ABMS platform the next post will talk much more about.
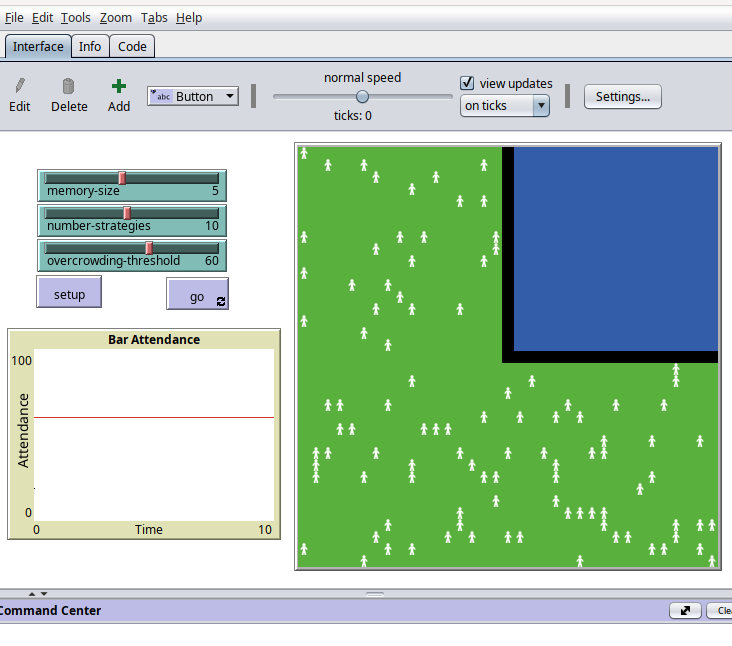
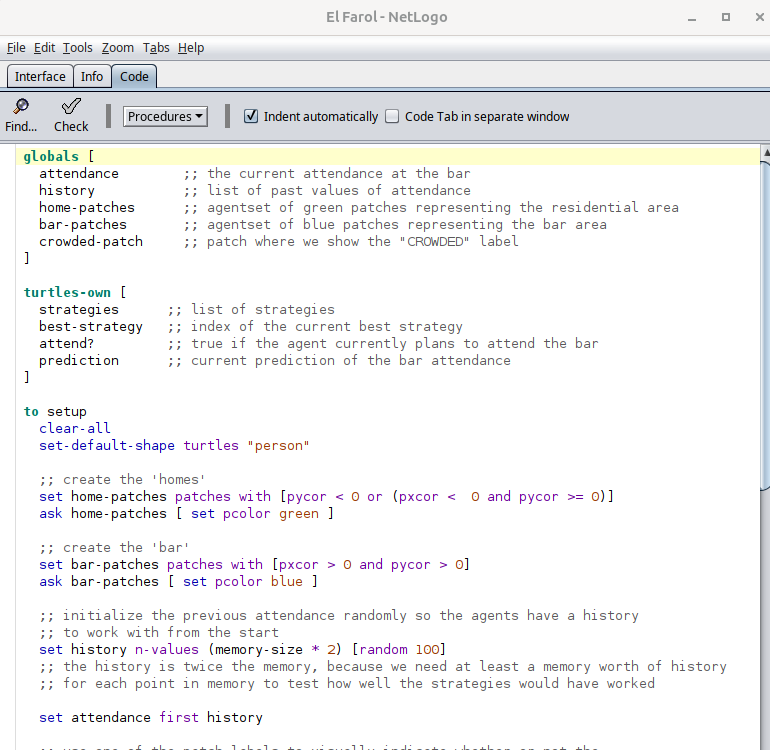
Here is part of the implementation in the platform’s code tab.
The wonderful lives of agents
It was only after some time that I realized that everything I just typed above has very little to do with what makes the simulation approach to something like El Farol so distinctive. Every agent is a simulated person instantiated as a simple computer program. These programs directly and/or indirectly interact with each other over the entire course of the simulation run.
Not all ABMS are written in object-oriented languages (or languages with support for object programming), but it helps to think of an agent program as an unique object with idiosyncratic and isolated state values and behaviors. E.g, a value could be how much money they own and a behavior being how they decide to spend it. Their state values can be updated (either within the agent program or externally by the simulation itself) as a direct or indirect consequence of their behavior.
Exactly how all of these little people are activated by the simulation to make their decisions and how their state values are updated is a rather convoluted issue. The next post will focus on it specifically. For now, simply assume that it happens through magical fairy dust. There is no need at the moment to delve into it any deeper. With that out of the way, let us continue forward.
Assume, for the sake of argument, that all of these little people have the same constants. Every little person is of the same type, even if he or she may have a different life progression when the simulation starts. In the El Farol case , this means that every agent has the same number of strategies, memory size, overcrowding threshold, and the same method of making and/or improving choices.
However, there is always some random element initially assigned to each agent program at the beginning of the simulation run. Again, in the El Farol case, it is randomly distributed strategies — and the composition of each usable prediction strategy itself is randomly generated at the start of each unique simulation run. To recap:
- Every simulated parson created at the start of the model is a separate and unique software object.
- That separate and unique object has distinct state values that dynamically change over time as a direct or indirect consequence of its behavior.
- At the start of a simulation run, all agent-objects are initialized with randomly assigned initial attributes/conditions.
What this means is that, for each unique program in thousands of interacting programs, there is a corresponding unique life history inside the simulation. This factor alone accounts for some pretty wild variance in ABMS simulation runs.
Imagine thousands of these little guys, all running around and separately making decisions based on information culled from their accumulated life experience. The fact that every simulation run features thousands of simulated individual people with independent yet loosely coupled decision trajectories over time makes no two simulation runs totally identical. Despite all of the agents being of the same type the population itself is not really homogenous.
And, in many cases, simulations do not even assume that all agents are of the same type. There may be an interacting population with different decision methods or different overarching core attributes. This is precisely what makes ABMS so interesting — and also, as in the ICL controversy — so potentially volatile. But how do we know the assumptions they make are correct? Or, to put it in Woolridge’s terms, how do we make the assumptions explicit?
Assumptions about assumptions
The great chain of being
What would it really mean to make the assumptions of something like the El Farol Bar Problem explicit? There is, not coincidentally, a dispute currently raging about this overall topic outside of ABMS. How to make the assumptions of a computational implementation transparent is a complicated matter ven in areas with far more certainty about their core theoretical claims and methods of representation than ABMS.
Eric Winsberg, in his study Science in the Age of Computer Simulation, writes at great length about how the assumptions made by a computer implementation of a theoretical concept may differ consequentially from the assumptions the concept itself makes.
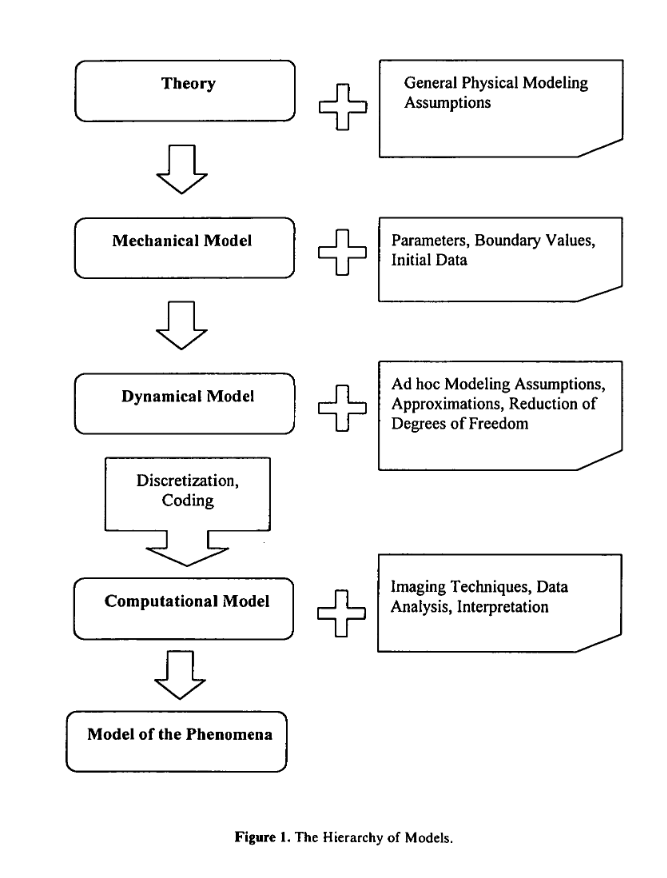
In a 1999 paper, Winsberg illustrates this with a “hierarchy of models” that are traversed in the implementation of physical theories as computer simulations. First, the theory is applied to real world systems as a “mechanical model” — bare bones characterization of the system that allows us to identify the relevant family of equations corresponding to it. “When we characterize a system as being like a damped, harmonic oscillator, we have assigned a mechanical model to the system. ”
Next, the theoretical concept shrinks further: parameters, boundary values, initial conditions, and similar specifications now constrain the theory to a highly specific class of phenomena under study. It is now a dynamical model. However, just because it is now much more compact, less vague, and more concise than theory does not mean that it mathematically tractable and effectively solvable by a computer. Further work must be performed in order to transform it into a computational model.
The dynamical model’s equations are now converted into a form better suited for computerized manipulation. While the mathematical tractability of the model is now accounted for and the problem is solvable on a computer, it still may require further transformation to deal with the myriad of practical issues that come up during the sometimes messy process of full implementation.
Computational implementation
This is the stage at which ad-hoc modeling choices are made in order to make the computational model derived from the dynamical model much more efficient and manageable.
Ad hoc modeling includes such techniques as simplifying assumptions, removing degrees of freedom, and even substituting simpler empirical relationships for more complex, but also more theoretically founded laws. This model making can be eliminative or creative. The modeling can involve eliminating considerations from the dynamical model, or making up new ones. Sometimes simulationists ignore important factors or influences when creating their computational models because of the limitations of computational power. This is what I refer to as eliminative ad hoc modeling. In this case, the simulationist has one of two options: either to determine that the effects of this neglected factor are negligible or to make use of some sort of empirical “fudge factor” — creative ad hoc modeling — to make up for the absence of the neglected factor.
By the time the computational model is fully implemented on the computer, a new problem arises: the interpretation of the output data.
The synthetic data — and there is sometimes quite a lot of it — requires interpretation. It is now visualized using specialized techniques designed to help discover or illustrate patterns or relationships. Mathematical analysis is deployed to interpret the data and verify/validate the software implementation. Additional sources of knowledge — such as idiosyncratic observation of the implementation or the real world system corresponding to it — are also applied to finally transform the simulation implementation into a polished model of the physical system in question.
The closer one gets to the bottom of the chart, the more the model object — on its way from theory to fully realized simulation model — acquires assumptions autonomous from those made by the initial theoretical concept. These assumptions attach to the model object like barnacles, steadily accumulating with or without the conscious knowledge of Winsberg’s “simulationist.” Assumptions can certainly be made explicit, but it would require a rather laborious and time-intensive process to catch and trace their emergence over time.
Animals in the zoo
Rolling your own simulation framework, as the ICL team seem to have done, is likely bad from the perspective of both assumption legibility. The technical messiness of the implementation makes important assumptions harder to unearth. And one could argue, as Woolridge does, that the implementation in an unsuitable language like C takes the focus away from the problem being worked on due to all of the ad-hoc issues that come up during implementation.
However, it is not clear that a more standardized and problem-driven development environment eliminates the assumption issue either. As seen with Winsberg’s hierarchy of models, the black-boxing of low-level implementation represents the calcified end product of an enormous amount of assumptions (many ad-hoc). A well-made tool will, in any event, also suggest its own usage and point the user towards some courses of action and away from others.
Another issue about assumptions is less obvious. Winsberg’s paper argued that moving down the hierarchy of models from theoretical concept to a fully realized simulation model of phenomena made the finished product an autonomously existing object. It has familiar relation to the original theoretical concept behind it, but the process of making the computational artifact introduces assumptions (many of which are ad-hoc) that progressively diverge from the concept.
However, in moving from theory to dynamical model, one could at least have some degree of confidence that X or Y is like a damped, harmonic oscillator. The further one gets from problems in the physical sciences 7, the less ground truth there will be to validate problem representations and methods. Positing that nuclear arms control problems are like the cruel dilemmas facing two prisoners considering whether or not to snitch on each other cannot be justified as easily.
Moreover, social and behavioral science problems in particular are rife with various forms of observer-expectancy issues. Something I find amusing about the popularity of electoral forecasting simulation modeling (FiveThirtyEight, Split Ticket, Silver Bulletin, etc) and the model-like polls they ingest is the possibility that they might need to one day model their own effects on political behavior. The more accurate the tools are perceived to be at predicting the future, the likelier it will be that people made decisions based on those predictions.
The influence of user-facing modeling systems — from recommendation systems to large language models — on mass behavior online is much less hypothetical. People consciously game these systems to get more out of them. They also unconsciously adapt their own perceptions and actions around the system framing. Inasmuch as any kind of user-facing software is a model of some sort, it will always condition the behavior of the user around its basic assumptions.
The ambiguity, self-reference, and other similar factors surrounding simulation of social and behavioral systems, I think, is a large part of why we have such a big and rich zoo of simulation platforms in the first place. Alan Newell — one of the creators of the SOAR cognitive architecture — called for “unified theories of cognition” unified around platforms like SOAR. For better or worse, we must take a trip to the zoo instead.
The next episode
I had to get a lot of high-level content out of the way in this initial post. The next one is going to focus much more narrowly on a particular ABMS platform and a recurring component/element of ABMS implementation. The underlying conflict between explicitness of assumptions and abstraction of implementation introduced here will be examined in more greater detail.
Footnotes
-
It was one of the activities requiring what a relative dubbed “boredom loot.” This was her all-purpose term for my backpack full of books and the occasional laptop or portable game console. ↩
-
During one visit, a gorilla got pissed off at the gawking visitors and threw a tightly packed ball of feces at them. He wasn’t cut out for major league baseball — the shit ball dropped into the pit/moat/whatever separating the gorillas from the guests. But I’m sure at least a few people in the crowd found it relatable. ↩
-
My headcanon is that they’re actually super-lazy spies that the MSS has to find foolproof assignments for. ↩
-
I learned about this word from reading British magazines like The Register and unconsciously assimilated it. Later on, I heard from British friends that it was a semi-dismissive way of referring to “smart people you don’t have to understand or pay attention to.” ↩
-
While the first two headlines were fake, this one is actually real. ↩
-
I dislike crowded bars as well. I once made the mistake of going to a particularly boorish establishment in Northwest Washington D.C that (thankfully) no longer befouls the nation’s capitol with its infernal presence. I complimented a random woman’s tattoo and then was cowardly assaulted from behind by a local petty brigand. I assume that this nefarious individual was her boyfriend, but his exact relation to her has no bearing on the validity of his aggression towards me. ↩
-
My physics and physics-adjacent friends say I am being overly generous about physics here, but bear with me. ↩